S02-E03: Logistic Regression
Au programme de ce 3ème épisode : la régression logistique. Cette méthode permet de classer des données selon des valeurs discrètes. Par exemple, dire qu’un email est un spam ou pas, qu’un patient est critique ou pas, qu’une météo est ensoleillée, nuageuse, pluvieuse ou caniculaire … Cela induit quelques changements par rapport aux régressions linéaires que nous avons pu voir jusque là.

Classification
Une régression logistique permet de classer une donnée dans une case définie. Ces cases sont en nombre fini, contrairement à la régression linéaire où les prédictions pouvaient prendre une infinité de valeur (pensez au prix de la maison).
Plus précisément, en régression logistique, nous allons mesurer la probabilité pour qu’une donnée soit dans une case plutôt qu’une autre. En définissant un seuil (le threshold), nous déduisons ensuite si la donnée est bien dans cette case (le seuil est dépassé) ou pas (le seuil n’est pas atteint).
Puisqu’une probabilité est comprise 0 et 1, le threshold est souvent choisi à 0.5 (pas de jaloux comme ça).
Pour calculer cette probabilité, nous faisons appel à la fonction Sigmoïde (aussi appelée Logistic Function), qui a la forme suivante :

En reprenant la notation theta et x , on obtient cette nouvelle équation de notre fonction h :

Logistic Regression Model
Puisque nous avons une nouvelle équation, nous devons mettre à jour nos autres équations, et notamment la Cost Function. Dans le cas de la régression logistique, la Cost Function dépend de la valeur y :

Avec ces équations, nous retrouvons un comportement similaire :
- si
h_theta(x) = y, alorsJ(theta) = 0 - si
y = 0et queh_thetatend vers 1, la Cost Function tend vers l’infini - si
y = 1et queh_thetatend vers 0, la Cost Function tend vers l’infini
Pour éviter de se trimballer avec deux équations en permanence, nous allons bénéficier du fait que y ne prend que deux valeurs possibles (0 ou 1) pour écrire notre Cost Function comme suit :

Alors certes, c’est moins beau et plus verbeux qu’avant, mais cela fait aussi bien le job ! D’ailleurs, on remarque que pour calculer les termes theta , on a la même formule pour calculer le Gradient Descent :

Multiclass Classification
Ok, donc nous venons de voir plein d’équations pour adapter nos calculs à ce nouveau modèle qui nous permet de prédire si Oui ou Non, notre donnée est dans une case. Mais qu’en est-il lorsque nous voulons faire de la classification multi-classe, comme avec la météo (pour être plus précis que : il va faire beau ou pas) ?
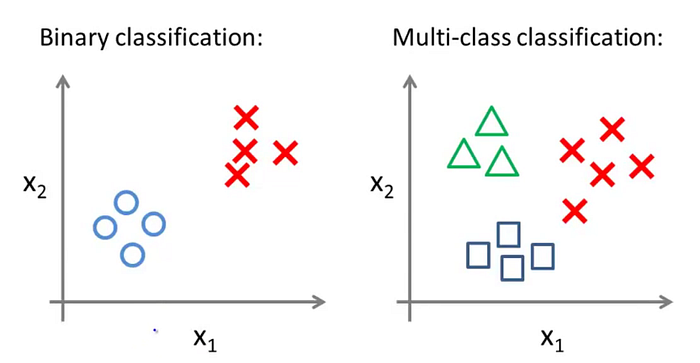
Pour cela, rien de plus simple, nous allons utiliser une technique qui s’appelle le One Vs All. Par exemple, prenons le cas de la météo avec 3 classes : ensoleillé, nuageux, pluvieux. Pour calculer la probabilité de *ensoleillé*, nous allons étudier la probabilité de ensoleillé face à tout le reste (nuageux + pluvieux).
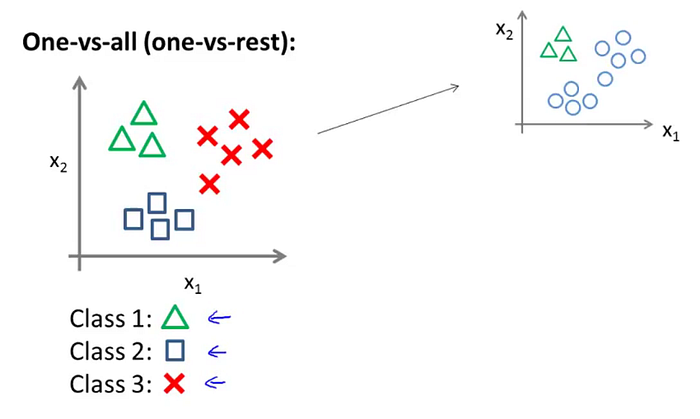
Voilà, c’est tout simple en fait, pas la peine de se prendre le choux !
Solving the Problem of Overfitting
Plus nous avançons dans notre voyage au pays de la donnée, plus nous rencontrons des obstacles (que nous franchirons, un par un, je vous le promets). Deux cas peuvent se présenter lorsque nous entraînons un modèle : underfitting et overfitting.
- Underfitting, c’est quand notre modèle est trop lâche, trop mou et n’a pas suffisamment appris de notre jeu d’entraînement. Peut-être est-il trop simple, peut-être utilise-t-il trop peu de features … ?
- Overfitting, c’est la cas inverse : quand notre modèle a trop appris sur le jeu d’entraînement. Tellement bien qu’il les connaît par coeur mais qu’il va être impossible pour lui de s’adapter à de nouvelles données à prédire. Pour contrer cela, il faut réduire le nombre de features (rendre le modèle plus simple et plus général) et faire de la régularisation (si vous vous demandez ce que c’est, continuez à lire, c’est juste en dessous).
Regularization
La régularisation consiste à garder un maximum de features, mais à réduire la magnitude (les valeurs de theta ) pour faire en sorte que toutes aient “la même importance” lors de l’élaboration du modèle. Par exemple, pour éviter que le prix en million d’euros d’une maison vienne écraser le nombre de toilettes (souvent 2 voire 3 grand max).
Minimiser la Cost Function
Nous allons voir la régularisation dans le cas d’une régression linéaire puis, dans un second temps, dans le cas d’une régression logistique.
Regularized Linear Regression
Vous l’avez en tête, pour déterminer les coefficients theta , nous cherchons à minimiser la Cost Function. Or, puisque nous appliquons une régularisation, nous allons atténuer l’impact des features en ajoutant un terme à la Cost Function :

Nous ajoutons la somme des carrés des theta(multipliée par lambda , le coefficient de régularisation). Puisque nous cherchons à minimiser ces theta , cela permet naturellement de les contenir.
Avec cette nouvelle équation, on dit que l’équation est régularisée.
Après le calcul, il ne reste plus qu’à déterminer les équations pour les theta via Gradient Descent :
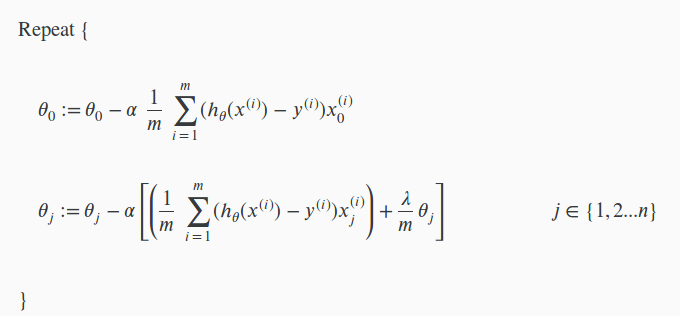
Vous aurez remarqué que nous ne régularisons pas theta_0 pour ne pas le pénaliser (si vous vous rappelez, nous ajoutons x_0 = 1 pour garder un biais)
Regularized Logistic Regression
Jetons un coup d’oeil à la régularisation dans le cas d’une régression logistique :
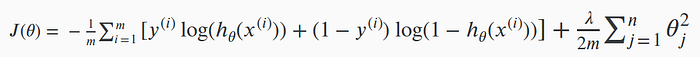
Comme vous l’observez, le principe est le même. Idem pour le calcul du Gradient Descent :
Conclusion
Et voilà une bonne partie de faite ! Beaucoup de nouvelles choses :
- la fonction sigmoïde pour la nouvelle Cost Function en regression logistique
- de nouvelles équations pour le Gradient Descent
- ajout de termes de régularisation pour les deux régressions linéaire et logistique pour “contenir” les valeurs de
theta
Je vous rassure, tout s’est très bien passé avec les exercices sous Octave/Matlab :

La prochaine partie parlera des réseaux de neurones ! Une partie que j’attends avec impatience car ce sera TOUT nouveau pour moi (le mooc précédent n’ayant pas du tout abordé cela).
La bise !
Next : Neural Networks : Representation
Previous : Linear Regression With Multiple Variables

